The New Scalable ETS ordered_set
The scalability of ETS tables of type ordered_set with the
write_concurrency option is substantially better in Erlang/OTP 22
than earlier releases. In some extreme cases, you can expect
more than 100 times better throughput in Erlang/OTP 22 compared to
Erlang/OTP 21. The cause of this improvement is a new data structure
called the contention adapting search tree (CA tree
for short). This blog post will give you insights into how the CA tree
works and show you benchmark results comparing the performance of ETS
ordered_set tables in OTP 21 and OTP 22.
Try it Out! #
[This escript]/blog/code/insert_disjoint_ranges.erl) makes it convenient for you
to try the new ordered_set implementation on your own machine with
Erlang/OTP 22+ installed.
The escript measures the time it takes for P Erlang processes to
insert N integers into an ordered_set ETS table, where P and N
are parameters to the escript. The CA tree is only utilized when the
ETS table options ordered_set and {write_concurrency, true} are
active. One can, therefore, easily compare the new data structure’s
performance with the old one (an AVL tree protected by a
single readers-writer lock). The write_concurrency option had no
effect on ordered_set tables before the release of Erlang/OTP 22.
We get the following results when running the escript on a developer laptop with two cores (Intel(R) Core(TM) i7-7500U CPU @ 2.70GHz):
$ escript insert_disjoint_ranges.erl old 1 10000000
Time: 3.352332 seconds
$ escript insert_disjoint_ranges.erl old 2 10000000
Time: 3.961732 seconds
$ escript insert_disjoint_ranges.erl old 4 10000000
Time: 6.382199 seconds
$ escript insert_disjoint_ranges.erl new 1 10000000
Time: 3.832119 seconds
$ escript insert_disjoint_ranges.erl new 2 10000000
Time: 2.109476 seconds
$ escript insert_disjoint_ranges.erl new 4 10000000
Time: 1.66509 seconds
We see that in this particular benchmark, the CA tree has superior scalability to the old data structure. The benchmark ran about twice as fast with the new data structure and four processes as with the old data structure and one process (the machine only has two cores). We will look at the performance and scalability of the new CA tree-based implementation in greater detail later after describing how the CA tree works.
The Contention Adapting Search Tree in a Nutshell #
The key feature that distinguishes the CA tree from other concurrent data structures is that the CA tree dynamically changes its synchronization granularity based on how much contention is detected inside the data structure. This way, the CA tree can avoid the performance and memory overheads that come from using many unnecessary locks without sacrificing performance when many operations happen in parallel. For example, let us imagine a scenario where the CA tree is initially populated from many threads in parallel, and then it is only used from a single thread. In this scenario, the CA tree will adapt to use fine-grained synchronization in the population phase (when fine-grained synchronization reduces contention). The CA tree will then change to use coarse-grained synchronization in the single-threaded phase (when coarse-grained synchronization reduces the locking and memory overheads).
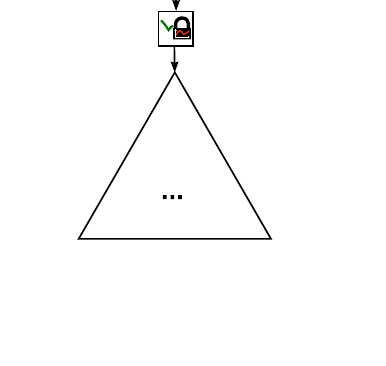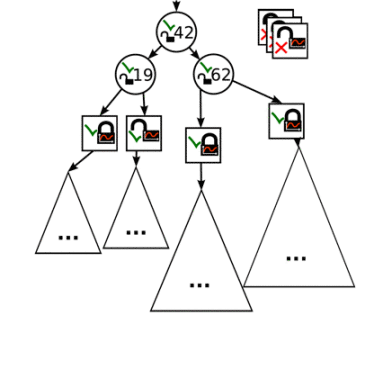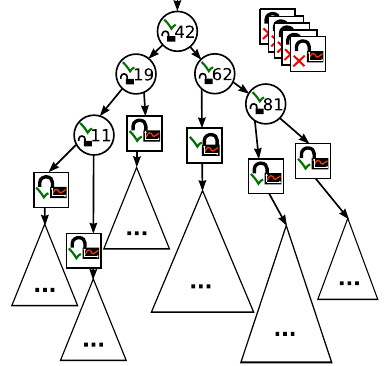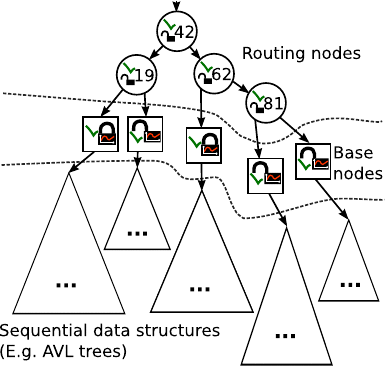
The structure of a CA tree is illustrated in the following picture:

The actual items stored in the CA tree are located in sequential data structures in the bottom layer. These sequential data structures are protected by the locks in the base nodes in the middle layer. The base node locks have counters associated with them. The counter of a base node lock is increased when contention is detected in the base node lock and decreased when no such contention is detected. The value of this base node lock counter decides if a split or a join should happen after an operation has been performed in a base node. The routing nodes at the top of the picture above form a binary search tree that directs the search for a particular item. A routing node also contains a lock and a flag. These are used when joining base nodes. The details of how splitting and joining work will not be described in this article, but the interested reader can find a detailed description in this CA tree paper (preprint PDF). We will now illustrate how the CA tree changes its synchronization granularity by going through an example:
-
Initially, a CA tree only consists of a single base node with a sequential data structure as is depicted in the picture below:

-
If parallel threads access the CA tree, the value of a base node’s counter may eventually reach the threshold that indicates that the base node should be split. A base node split divides the items in a base node between two new base nodes and replaces the original base node with a routing node where the two new base nodes are rooted. The following picture shows the CA tree after the base node pointed to by the tree’s root has been split:

-
The process of base node splitting will continue as long as there is enough contention in base node locks or until the max depth of the routing layer is reached. The following picture shows how the CA tree looks like after another split:

-
The synchronization granularity may differ in different parts of a CA tree if, for example, a particular part of a CA tree is accessed more frequently in parallel than the rest. The following picture shows the CA tree after yet another split:

-
The following picture shows the CA tree after the fourth split:

-
The following picture shows the CA tree after the fifth split:

-
Two base nodes holding adjacent ranges of items can be joined. Such a join will be triggered after an operation sees that a base node counter’s value is below a certain threshold. Remember that a base node’s counter is decreased if a thread does not experience contention when acquiring the base node’s lock.

-
As you might have noticed from the illustrations above, splitting and joining results in that old base nodes and routing nodes gets spliced-out from the tree. The memory that these nodes occupy needs to be reclaimed, but this can not happen directly after they have got spliced-out as some threads might still be reading them. The Erlang run-time system has a mechanism called thread progress, which the ETS CA tree implementation uses to reclaim these nodes safely.

Click here to see an animation of the example.
{kind=link}
Benchmark #
The performance of the new CA tree-based ETS ordered_set
implementation has been evaluated in a benchmark that measures the
throughput (operations per second) in many scenarios. The
benchmark lets a configurable number of Erlang processes perform a
configurable distribution of operations on a single ETS table. The
curious reader can find the source code of the benchmark in the test
suite for
ETS.
The following figures show results from this benchmark on a machine with two Intel(R) Xeon(R) CPU E5-2673 v4 @ 2.30GHz (32 cores in total with hyper-threading). The average set size in all scenarios was about 500K. More details about the benchmark machine and configuration can be found on this page.








We see that the throughput of the CA tree-based ordered_set (OTP-22)
improves when we add cores all the way up to 64 cores, while the old
implementation’s (OTP-21) throughput often gets worse when more
processes are added. The old implementation’s write operations are
serialized as the data structure is protected by a single
readers-writer lock. The slowdown of the old version when adding more
cores is mainly caused by increased communication overhead when more
cores try to acquire the same lock and by the fact that the competing
cores frequently invalidate each other’s cache lines.
The graph for the 100% lookups scenario (the last graph in the list of
graphs above) looks a bit strange at first sight. Why does the CA tree
scale so much better than the old implementation in this scenario? The
answer is almost impossible to guess without knowing the
implementation details of the ordered_set table type. First of all,
the CA tree uses the same readers-writer lock implementation
for its base node locks as the old implementation uses to protect the whole
table. The difference is thus not due to any lock differences. The
default ordered_set implementation (the one that is active when
write_concurrency is off) has an optimization that mainly improves
usage scenarios where a single process iterates over items of the
table, for example, with a sequence of calls to the ets:next/2
function. This optimization keeps a static stack per table. Some
operations use this stack to reduce the number of tree nodes that need
to be traversed. For example, the ets:next/2 operation does not need
to recreate the stack, if the top of the stack contains the same key
as the one passed to the operation (see
here). As there is only one static stack per
table and potentially many readers (due to the readers-writer lock),
the static stack has to be reserved by the thread that is currently
using it. Unfortunately, the static stack handling is a scalability
bottleneck in scenarios like the one with 100% lookups above. The CA
tree implementation does not have this type of optimization, so it
does not suffer from this scalability bottleneck. However, this also
means that the old implementation may perform better than the new one
when the table is mainly sequentially accessed. One example of when
the old implementation (that still can be used by setting the
write_concurrency option to false) performs better is the single
process case of the 10% insert, 10% delete, 40% lookup and 40%
nextseq1000 (a sequence of 1000 ets:next/2 calls) scenario (the
second last graph in the list of graphs above).
Therefore, we can conclude that that turning on write_concurrency
for an ordered_set table is probably a good idea if the table is
accessed from multiple processes in parallel. Still, turning off
write_concurrency might be better if you mainly access the table
sequentially.
A Note on Decentralized Counters #
The CA tree implementation was not the only optimization introduced in
Erlang/OTP 22, affecting the scalability of ordered_set with
write_concurrency. An optimization that decentralized counters in
ordered_set tables with write_concurrency turned on was also
introduced in Erlang/OTP 22 (see here). An
option to enable the same optimization in all table types was
introduced in Erlang/OTP 23 (see here). You can
find benchmark results comparing the scalability of the tables with
and without decentralized counters here.
Further Reading #
The following paper describes the CA tree and some optimizations (of which some have not been applied to the ETS CA tree yet) in much more detail than this blog post. The paper also includes an experimental comparison with related data structures.
- A Contention Adapting Approach to Concurrent Ordered Sets (preprint). Journal of Parallel and Distributed Computing, 2018. Konstantinos Sagonas and Kjell Winblad
There is also a lock-free variant of the CA tree that is described in the following paper. The lock-free CA tree uses immutable data structures in its base nodes to substantially reduce the amount of time range queries, and similar operations can conflict with other operations.
- Lock-free Contention Adapting Search Trees (preprint). In the proceedings of the 30th Symposium on Parallelism in Algorithms and Architectures (SPAA 2018). Kjell Winblad, Konstantinos Sagonas, and Bengt Jonsson.
The following paper, which discusses and evaluates a prototypical CA tree implementation for ETS, was the first CA tree-related paper.
- More Scalable Ordered Set for ETS Using Adaptation (preprint). In Thirteenth ACM SIGPLAN workshop on Erlang (2014). Konstantinos Sagonas and Kjell Winblad
You can look directly at the ETS CA tree source code if you are interested in specific implementation details. Finally, it might also be interesting to look at the author’s Ph.D. thesis if you want to get more links to related work or want to know more about the motivation for concurrent data structures that adapt to contention.
Conclusion #
The Erlang/OTP 22 release introduced a new ETS ordered_set
implementation that is active when the write_concurrency option is
turned on. This data structure (a contention adapting search tree) has
superior scalability to the old data structure in many different
scenarios and a design that gives it excellent performance in a variety
of scenarios that benefit from different synchronization
granularities.